Урлопен душит меня новыми строками
Я соскребаю простые текстовые файлы с URL.
def scrape_contents_ex(url):
data = urllib2.urlopen(url)
return data.read()
Проблема в том, что строка, которую она дает, забита символами новой строки и табуляции "\t", "\r" и т. Д.
Пример:
Вот веб-страница 
Когда я печатаю вывод строки в python, он рендерится с различными символами \:
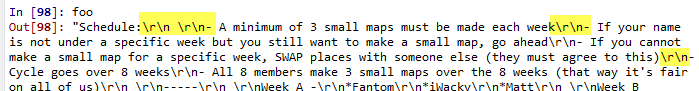
Я не знаю, как правильно обрабатывать вывод, который я прочитал из урлопена. Я хочу хранить это содержимое в postgresql. Более того, у меня есть еще одно осложнение, при котором контент, скорее всего, даст результаты в юникоде (китайские иероглифы, кириллица и т. Д.).
Как правильно и надежно читать и хранить это?
3 ответа
Вы можете использовать метод str.split(), хотя есть много вариантов решения этой конкретной проблемы.
Из документации по Python 3.5.1:
>>> '1,2,3'.split(',')
['1', '2', '3']
>>> '1,2,3'.split(',', maxsplit=1)
['1', '2,3']
>>> '1,2,,3,'.split(',')
['1', '2', '', '3', '']
Вы хотели бы что-то вроде
return data.read().split('\n\t')
Результатом является список строк, встречающихся между любыми экземплярами '\n\t' в вашей исходной строке.
Вам нужно использовать библиотеки 'urllib', 'urllib2', чтобы избежать кодирования.
Вы можете проверить следующую ссылку https://docs.python.org/2/howto/urllib2.html
foo это строка байтов в вашем случае. Если это представляет текст; Вы должны декодировать его в Unicode перед сохранением в PostgreSQL: text = foo.decode(character_encoding) Кодировка может зависеть от Content-Type. См . Хороший способ получить кодировку / кодировку ответа HTTP в Python.
Затем вы вводите foo по приглашению, ipython пытается отобразить foo объект, и это может вызвать repr(foo),
Что ты видишь: "a\nb" (результат repr() call) является печатным представлением объекта Python с типом str (type(foo) == str). Строковые литералы Python используют тот же синтаксис. Обратная косая черта является специальным внутри строковых литералов, например, "\n" это один символord("\n") == 10). Если вы хотите создать строку, содержащую два символа: backslash + n тогда вы должны избежать обратной косой черты или использовать необработанные строковые литералы:
>>> "\\n" == r"\n" != "\n"
True