Об интернировании строк и альтернативах
У меня есть большой файл, который, по сути, содержит такие данные, как:
Netherlands,Noord-holland,Amsterdam,FooStreet,1,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,2,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,3,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,4,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,5,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,1,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,2,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,3,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,4,...,...
Netherlands,Noord-holland,Amstelveen,BazDrive,1,...,...
Netherlands,Noord-holland,Amstelveen,BazDrive,2,...,...
Netherlands,Noord-holland,Amstelveen,BazDrive,3,...,...
Netherlands,Zuid-holland,Rotterdam,LoremAve,1,...,...
Netherlands,Zuid-holland,Rotterdam,LoremAve,2,...,...
Netherlands,Zuid-holland,Rotterdam,LoremAve,3,...,...
...
Это мультигигабайтный файл. У меня есть класс, который читает этот файл и выставляет эти строки (записи) как IEnumerable<MyObject>, это MyObject имеет несколько свойств (Country, Province, City,...) так далее.
Как вы можете видеть, есть много дублирования данных. Я хочу продолжать выставлять основные данные как IEnumerable<MyObject>, Тем не менее, другой класс может (и, вероятно, будет) создавать иерархическое представление / структуру этих данных, например:
Netherlands
Noord-holland
Amsterdam
FooStreet [1, 2, 3, 4, 5]
BarRoad [1, 2, 3, 4]
...
Amstelveen
BazDrive [1, 2, 3]
...
...
Zuid-holland
Rotterdam
LoremAve [1, 2, 3]
...
...
...
...
Читая этот файл, я делаю это:
foreach (line in myfile) {
fields = line.split(",");
yield return new MyObject {
Country = fields[0],
Province = fields[1],
City = fields[2],
Street = fields[3],
//...other fields
};
}
Теперь к актуальному вопросу: я мог бы использовать string.Intern() интернировать Страну, Провинцию, Город и Стриты (это главные "вилайны", MyObject имеет несколько других свойств, не имеющих отношения к вопросу).
foreach (line in myfile) {
fields = line.split(",");
yield return new MyObject {
Country = string.Intern(fields[0]),
Province = string.Intern(fields[1]),
City = string.Intern(fields[2]),
Street = string.Intern(fields[3]),
//...other fields
};
}
Это позволит сэкономить около 42% памяти (проверено и измерено) при хранении всего набора данных в памяти, поскольку все повторяющиеся строки будут ссылаться на одну и ту же строку. Кроме того, при создании иерархической структуры с большим количеством LINQ .ToDictionary() метод ключей (страна, провинция и т. д.) респ. словари будут намного эффективнее.
Однако один из недостатков (за исключением небольшой потери производительности, которая не является проблемой) использования string.Intern() в том, что строки больше не будут собирать мусор. Но когда я закончу со своими данными, я захочу собрать весь этот мусор (в конце концов).
Я мог бы использовать Dictionary<string, string> "интернировать" эти данные, но мне не нравятся "накладные расходы" на наличие key а также value где я, на самом деле, интересуюсь только key, Я мог бы установить value в null или использовать ту же строку в качестве значения (что приведет к той же ссылке в key а также value). Это всего лишь небольшая цена в несколько байтов, но это все же цена.
Что-то вроде HashSet<string> имеет больше смысла для меня. Однако я не могу получить ссылку на строку в HashSet; Я могу видеть, содержит ли HashSet определенную строку, но не получить ссылку на этот конкретный экземпляр расположенной строки в HashSet. Я мог бы реализовать свой собственный HashSet для этого, но мне интересно, какие другие решения вы любезно можете предложить Stackruers.
Требования:
- Мой класс "FileReader" должен постоянно выставлять
IEnumerable<MyObject> - Мой класс "FileReader" может делать вещи (например,
string.Intern()) оптимизировать использование памяти -
MyObjectкласс не может измениться; Я не буду делатьCityучебный класс,Countryкласс и т. д. и естьMyObjectвыставить их как свойства, а не простоstringсвойства - Цель состоит в том, чтобы (более) эффективно использовать память путем дедупликации большинства дублирующих строк в
Country,Province,Cityтак далее.; как это достигается (например, интернирование строк, внутренний хэш-сет / коллекция / структура чего-либо) не имеет значения. Тем не мение: - Я знаю, что могу поместить данные в базу данных или использовать другие решения в этом направлении; Я не заинтересован в подобных решениях.
- Скорость имеет второстепенное значение; чем быстрее, тем лучше, но (незначительная) потеря производительности при чтении / повторении объектов не представляет проблемы
- Поскольку это длительный процесс (например, служба Windows работает 24/7/365), который иногда обрабатывает большую часть этих данных, я хочу, чтобы данные собирались мусором по окончании работы; Интернирование строк прекрасно работает, но в конечном итоге приведет к огромному пулу строк с большим количеством неиспользуемых данных
- Я хотел бы, чтобы любые решения были "простыми"; добавление 15 классов с помощью P/Invokes и встроенной сборки (преувеличено) не стоит усилий. Возможность сопровождения кода занимает одно из первых мест в моем списке.
Это больше "теоретический" вопрос; это просто из любопытства / интереса, о котором я спрашиваю. Нет " реальной " проблемы, но я вижу, что в подобных ситуациях это может быть проблемой для кого-то.
Например: я мог бы сделать что-то вроде этого:
public class StringInterningObject
{
private HashSet<string> _items;
public StringInterningObject()
{
_items = new HashSet<string>();
}
public string Add(string value)
{
if (_items.Add(value))
return value; //New item added; return value since it wasn't in the HashSet
//MEH... this will quickly go O(n)
return _items.First(i => i.Equals(value)); //Find (and return) actual item from the HashSet and return it
}
}
Но с большим набором (для дедупликации) строк это быстро увязнет. Я мог бы взглянуть на справочный источник для HashSet или Dictionary или... и создать подобный класс, который не возвращает bool для Add() метод, но фактическая строка найдена во внутреннем / ведре.
Лучшее, что я мог придумать до сих пор, это что-то вроде:
public class StringInterningObject
{
private ConcurrentDictionary<string, string> _items;
public StringInterningObject()
{
_items = new ConcurrentDictionary<string, string>();
}
public string Add(string value)
{
return _items.AddOrUpdate(value, value, (v, i) => i);
}
}
Который имеет "штраф" за наличие ключа и значения, когда меня интересует только ключ. Хотя всего несколько байтов, маленькая цена, чтобы заплатить. По совпадению это также дает на 42% меньше использования памяти; тот же результат, что и при использовании string.Intern() доходность.
Tolanj разработал System.Xml.NameTable:
public class StringInterningObject
{
private System.Xml.NameTable nt = new System.Xml.NameTable();
public string Add(string value)
{
return nt.Add(value);
}
}
(Я удалил блокировку и строку. Пустая проверка (последняя, поскольку NameTable уже делает это))
xanatos придумала CachingEqualityComparer:
public class StringInterningObject
{
private class CachingEqualityComparer<T> : IEqualityComparer<T> where T : class
{
public System.WeakReference X { get; private set; }
public System.WeakReference Y { get; private set; }
private readonly IEqualityComparer<T> Comparer;
public CachingEqualityComparer()
{
Comparer = EqualityComparer<T>.Default;
}
public CachingEqualityComparer(IEqualityComparer<T> comparer)
{
Comparer = comparer;
}
public bool Equals(T x, T y)
{
bool result = Comparer.Equals(x, y);
if (result)
{
X = new System.WeakReference(x);
Y = new System.WeakReference(y);
}
return result;
}
public int GetHashCode(T obj)
{
return Comparer.GetHashCode(obj);
}
public T Other(T one)
{
if (object.ReferenceEquals(one, null))
{
return null;
}
object x = X.Target;
object y = Y.Target;
if (x != null && y != null)
{
if (object.ReferenceEquals(one, x))
{
return (T)y;
}
else if (object.ReferenceEquals(one, y))
{
return (T)x;
}
}
return one;
}
}
private CachingEqualityComparer<string> _cmp;
private HashSet<string> _hs;
public StringInterningObject()
{
_cmp = new CachingEqualityComparer<string>();
_hs = new HashSet<string>(_cmp);
}
public string Add(string item)
{
if (!_hs.Add(item))
item = _cmp.Other(item);
return item;
}
}
(Немного изменен, чтобы "соответствовать" моему интерфейсу "Add()")
public class StringInterningObject
{
private Dictionary<string, string> _items;
public StringInterningObject()
{
_items = new Dictionary<string, string>();
}
public string Add(string value)
{
string result;
if (!_items.TryGetValue(value, out result))
{
_items.Add(value, value);
return value;
}
return result;
}
}
Мне просто интересно, может быть, есть более аккуратный / лучший / более крутой способ "решить" мою (не так много актуальную) проблему. Теперь у меня достаточно вариантов 
Вот некоторые цифры, которые я придумал для некоторых простых, коротких предварительных тестов:
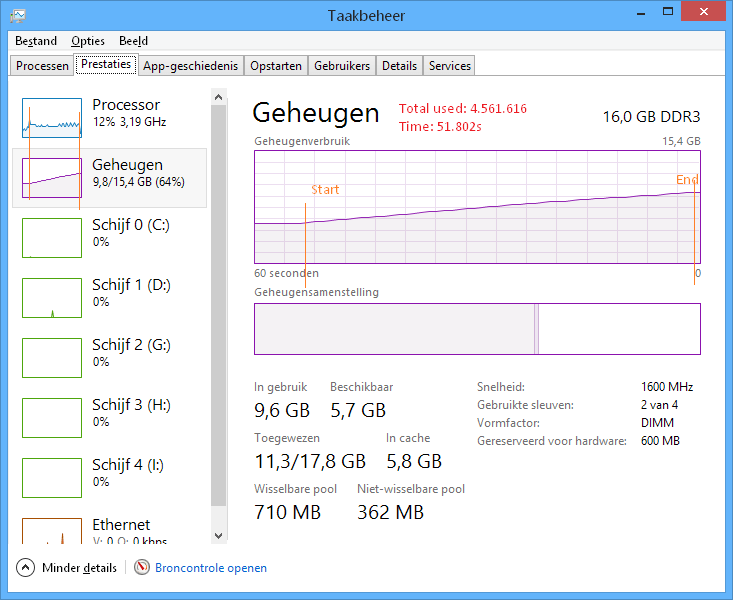
Не оптимизирован
Память: ~4,5 Гб
Время загрузки: ~52 с
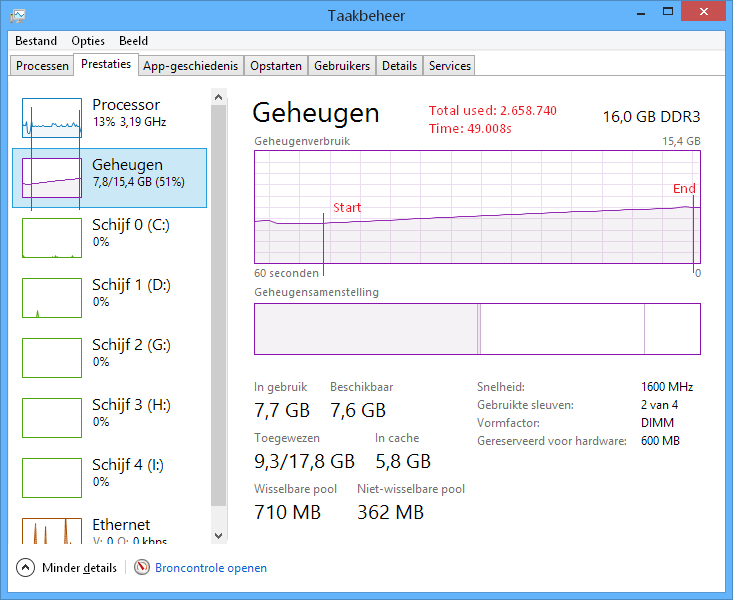
StringInterningObject (см. Выше, ConcurrentDictionary вариант)
Память: ~2,6 Гб
Время загрузки: ~49 с
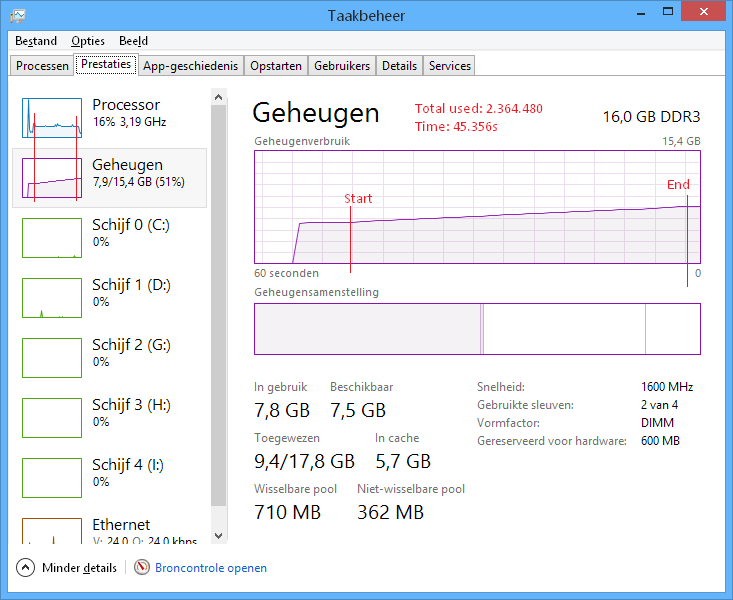
string.Intern()
Память: ~2,3 Гб
Время загрузки: ~45с
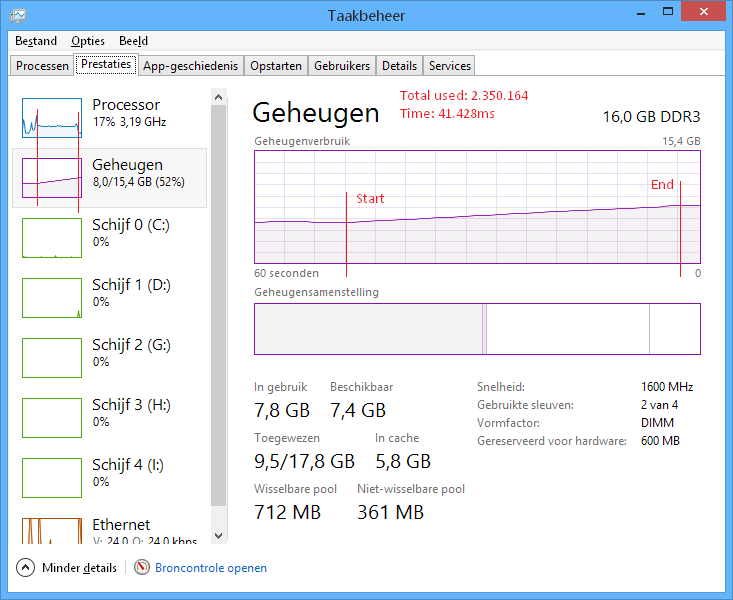
System.Xml.NameTable
Память: ~2,3 Гб
Время загрузки: ~41с
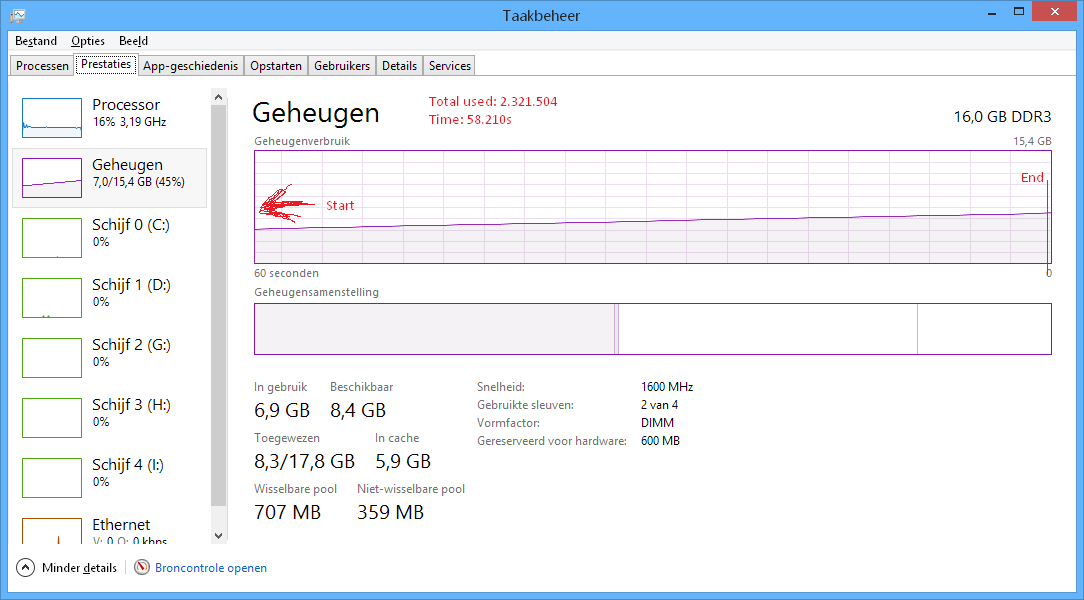
CachingEqualityComparer
Память: ~2,3 Гб
Время загрузки: ~58с
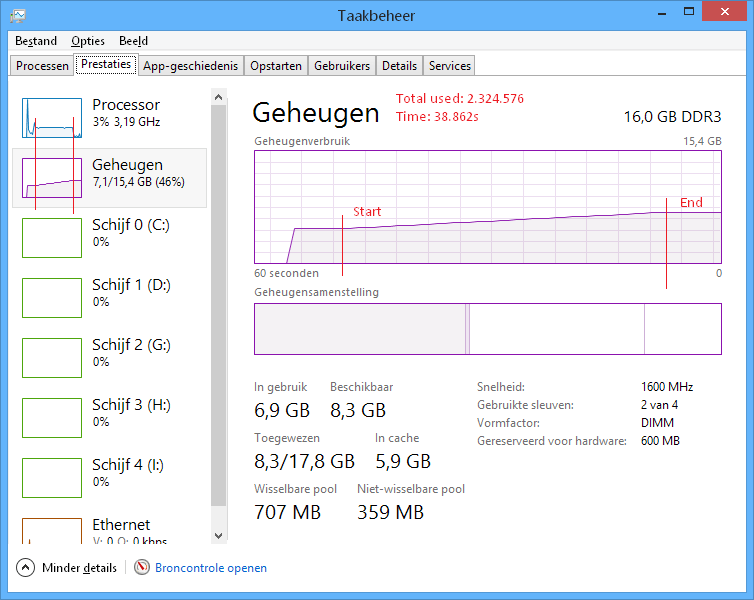
StringInterningObject (см. Выше, (не одновременно) Dictionary вариант) согласно запросу Хенка Холтермана:
Память: ~2,3 Гб
Время загрузки: ~39 с
Несмотря на то, что цифры не очень точны, кажется, что многие выделения памяти для неоптимизированной версии на самом деле замедляются больше, чем при использовании string.Intern() или выше StringInterningObject s, что приводит к (немного) большему времени загрузки. Также, string.Intern() кажется, "выиграть" от StringInterningObject но не с большим отрывом; << Смотрите обновления.
2 ответа
У меня было именно это требование, и я действительно спрашивал об этом, но не с подробностями вашего вопроса, без полезных ответов. Одна из встроенных опций - это (System.Xml).NameTable, который в основном представляет собой объект атомизации строк, который мы и искали (мы фактически перешли к Intern, потому что мы сохраняем эти строки для приложения. -Жизнь).
if (name == null) return null;
if (name == "") return string.Empty;
lock (m_nameTable)
{
return m_nameTable.Add(name);
}
на приватной NameTable
http://referencesource.microsoft.com/ показывает, что он реализован в виде простой хеш-таблицы, то есть хранит только одну ссылку на строку.
Даунсайд? это полностью специфично для строки. Если вы сделаете перекрестный тест на память / скорость, мне будет интересно увидеть результаты. Мы уже активно использовали System.Xml, и, конечно, это может показаться не таким уж естественным, если вы этого не сделали.
Если есть сомнения, обманывайте!:-)
public class CachingEqualityComparer<T> : IEqualityComparer<T> where T : class
{
public T X { get; private set; }
public T Y { get; private set; }
public IEqualityComparer<T> DefaultComparer = EqualityComparer<T>.Default;
public bool Equals(T x, T y)
{
bool result = DefaultComparer.Equals(x, y);
if (result)
{
X = x;
Y = y;
}
return result;
}
public int GetHashCode(T obj)
{
return DefaultComparer.GetHashCode(obj);
}
public T Other(T one)
{
if (object.ReferenceEquals(one, X))
{
return Y;
}
if (object.ReferenceEquals(one, Y))
{
return X;
}
throw new ArgumentException("one");
}
public void Reset()
{
X = default(T);
Y = default(T);
}
}
Пример использования:
var comparer = new CachingEqualityComparer<string>();
var hs = new HashSet<string>(comparer);
string str = "Hello";
string st1 = str.Substring(2);
hs.Add(st1);
string st2 = str.Substring(2);
// st1 and st2 are distinct strings!
if (object.ReferenceEquals(st1, st2))
{
throw new Exception();
}
comparer.Reset();
if (hs.Contains(st2))
{
string cached = comparer.Other(st2);
Console.WriteLine("Found!");
// cached is st1
if (!object.ReferenceEquals(cached, st1))
{
throw new Exception();
}
}
Я создал средство сравнения равенства, которое "кэширует" последнее Equal Сроки это проанализировали:-)
Тогда все может быть заключено в подкласс HashSet<T>
/// <summary>
/// An HashSet<T;gt; that, thorough a clever use of an internal
/// comparer, can have a AddOrGet and a TryGet
/// </summary>
/// <typeparam name="T"></typeparam>
public class HashSetEx<T> : HashSet<T> where T : class
{
public HashSetEx()
: base(new CachingEqualityComparer<T>())
{
}
public HashSetEx(IEqualityComparer<T> comparer)
: base(new CachingEqualityComparer<T>(comparer))
{
}
public T AddOrGet(T item)
{
if (!Add(item))
{
var comparer = (CachingEqualityComparer<T>)Comparer;
item = comparer.Other(item);
}
return item;
}
public bool TryGet(T item, out T item2)
{
if (Contains(item))
{
var comparer = (CachingEqualityComparer<T>)Comparer;
item2 = comparer.Other(item);
return true;
}
item2 = default(T);
return false;
}
private class CachingEqualityComparer<T> : IEqualityComparer<T> where T : class
{
public WeakReference X { get; private set; }
public WeakReference Y { get; private set; }
private readonly IEqualityComparer<T> Comparer;
public CachingEqualityComparer()
{
Comparer = EqualityComparer<T>.Default;
}
public CachingEqualityComparer(IEqualityComparer<T> comparer)
{
Comparer = comparer;
}
public bool Equals(T x, T y)
{
bool result = Comparer.Equals(x, y);
if (result)
{
X = new WeakReference(x);
Y = new WeakReference(y);
}
return result;
}
public int GetHashCode(T obj)
{
return Comparer.GetHashCode(obj);
}
public T Other(T one)
{
if (object.ReferenceEquals(one, null))
{
return null;
}
object x = X.Target;
object y = Y.Target;
if (x != null && y != null)
{
if (object.ReferenceEquals(one, x))
{
return (T)y;
}
else if (object.ReferenceEquals(one, y))
{
return (T)x;
}
}
return one;
}
}
}
Обратите внимание на использование WeakReference так что нет бесполезных ссылок на объекты, которые могут помешать сборке мусора.
Пример использования:
var hs = new HashSetEx<string>();
string str = "Hello";
string st1 = str.Substring(2);
hs.Add(st1);
string st2 = str.Substring(2);
// st1 and st2 are distinct strings!
if (object.ReferenceEquals(st1, st2))
{
throw new Exception();
}
string stFinal = hs.AddOrGet(st2);
if (!object.ReferenceEquals(stFinal, st1))
{
throw new Exception();
}
string stFinal2;
bool result = hs.TryGet(st1, out stFinal2);
if (!object.ReferenceEquals(stFinal2, st1))
{
throw new Exception();
}
if (!result)
{
throw new Exception();
}
TLDR: из моего текущего результата я использую string.intern, основанный на словаре стажер не имеет большого значения
edit2:
я публикую свои производственные результаты
public class TProduct
{
public int ProductId { get; set; }
public int BrandId { get; set; }
public string ProductName { get; set; }
public string WordName { get; set; }
public string BrandName { get; set; }
public string ProductNameClean { get; set; } //interned field
public string BrandNameClean { get; set; } //interned field
}
Возможно, 2/7 поля интернированы, поэтому результат не так хорош, как я ожидал. (Я ожидаю, что, по крайней мере, 2-3-кратное сокращение будет продолжаться таким образом, если это увеличит сложность)
- Продукт класса 2.5M
- 50.000 уникальных брендов
- 50.000 уникальных брендов чистых
| reduction |
| | ram mb | mb | % | |
|---------------------|--------|------|------|------------------|
| string | 680 | | | |
| string.intern | 513 | 167 | 25 | |
| string.intern(dict) | 500 | 154 | 26 | |
| byte[] | 486 | 194 | 29 | hard to maintain |
| byte[].CustomIntern | 447 | 233 | 34 | hard to maintain |
Также мне пришлось добавить byteArrayEqualityComparer в byte[].customIntern . иначе равно gethashcode не работает как положено.
edit1:
Если ASCII ( 256 символов латинско-английский алфавит) подходит для вас.
преобразовать все строки в байт []. И используйте byte[] intern .
но это может создать много непредвиденных проблем.
также вам может понадобиться получить массив символов и, если нужно проверить, является ли его числовое значение больше 256., чтобы убедиться, выведите исключение. если ваш алфавит из списка записей хорош, чтобы пойти.
Из базы данных в byteClass
var AllDbResults_2mRec = new List<MyByteClass>();
foreach (var fields in DbRowProvider)
AllDbResults_2mRec.Add(
new MyClass {
Country = byteArrayInterningObject.Intern(fields[0].ASCII_bytes() ),
Province = byteArrayInterningObject.Intern(fields[1].ASCII_bytes() ),
City = byteArrayInterningObject.Intern(fields[2].ASCII_bytes() ),
} );
когда вы ищете 2 миллиона записей MyByteClass.
Вы отфильтровали до 20 записей (например)
MyByteClass[] results_asByte = AllDbResults_2mRec .Search("tokyo");
MyClass[] results = results_asByte
.Select(x=> MyClass.From_Byte(x) )
.ToArray();
Обязательные классы
class MyClass
{
string[] Country ;
string[] Province;
string[] City ;
public static From_Byte(MyByteClass mbc)
{
return new MyClass {
Country = mbc.Country.ASCII_string() ),
Province = mbc.Province.ASCII_string() ),
City = mbc.City.ASCII_string() ),
};
}
}
class MyByteClass
{
byte[] Country ;
byte[] Province;
byte[] City ;
}
public static class AsciiExt
{
// guarantee single byte per char. other one return multi byte for single char like € æ ß im not sure . but i chnaged it in my production code
public static byte[] ASCII_Bytes(this string str)
{
if (str == null)
return new byte[0];
var byteArr = new byte[str.Length];
for (int i = 0; i < str.Length; i++)
{
byteArr[i] = (byte)str[i]; //utf16 - already ascii compliant??
}
return byteArr;
}
public static byte[] ASCII_bytes(this string str)
{
return str == null ?
new byte[0] : Encoding.ASCII.GetBytes(str);
}
public static string ASCII_String(this byte[] byteArr)
{
return byteArr == null ?
string.Empty :
Encoding.ASCII.GetString(byteArr);
}
}
public class byteArrayInterningObject
{
private Dictionary<byte[], byte[]> _items;
public byteArrayInterningObject()
{
_items = new Dictionary<byte[], byte[]>();
}
public string Add(byte[] value)
{
string result;
if (!_items.TryGetValue(value, out result))
{
_items.Add(value, value);
return value;
}
return result;
}
}