Что такое строка кода?
Я понимаю, что нет однозначно "правильного" ответа на этот вопрос, но когда люди говорят о строках кода, что они имеют в виду? Например, в C++ вы считаете пустые строки? Комментарии? линии с открытой или закрытой скобкой?
Я знаю, что некоторые люди используют LoC в качестве меры производительности, и мне интересно, существует ли здесь стандартное соглашение. Кроме того, я думаю, что есть способ заставить различные компиляторы считать строки кода - есть ли там стандартное соглашение?
22 ответа
Нет, стандартного соглашения не существует, и каждый инструмент, который их учитывает, будет немного отличаться.
Это может заставить вас спросить: "Почему тогда я буду использовать LOC в качестве меры производительности?" и ответ таков: потому что на самом деле не имеет значения, как вы подсчитываете строку кода, при условии, что вы подсчитываете их последовательно, вы можете получить представление об общем размере проекта по отношению к другим.
Взгляните на статью из Википедии, особенно раздел " Измерение SLOC ":
Существует два основных типа мер SLOC: физический SLOC и логический SLOC. Конкретные определения этих двух показателей различаются, но наиболее распространенное определение физического SLOC- это количество строк в тексте исходного кода программы, включая строки комментариев. Пустые строки также включены, если только строки кода в разделе не содержат более 25% пустых строк. В этом случае пустые строки, превышающие 25%, не учитываются в строках кода.
Логические меры SLOC пытаются измерить количество "операторов", но их конкретные определения привязаны к конкретным компьютерным языкам (одна простая логическая мера SLOC для C-подобных языков программирования - это число точек с запятой в конце оператора). Гораздо проще создавать инструменты для измерения физического SLOC, а физические определения SLOC легче объяснить. Однако физические меры SLOC чувствительны к логически нерелевантным соглашениям о форматировании и стилях, в то время как логические SLOC менее чувствительны к соглашениям о форматировании и стилях. К сожалению, меры SLOC часто указываются без их определения, и логический SLOC часто может существенно отличаться от физического SLOC.
Рассмотрим этот фрагмент кода на C как пример неоднозначности, возникшей при определении SLOC:
for (i=0; i<100; ++i) printf("hello"); /* How many lines of code is this? */В этом примере мы имеем:
- 1 Физические строки кода LOC
- 2 логические строки кода lLOC (для выписки и выписки printf)
- 1 строка комментария
[...]
Я бы сказал
- количество комментариев
- количество пустых строк, потому что они важны для читабельности, но не более, чем одна
- строки с фигурными скобками тоже учитываются, но применяются те же правила, что и для пустых строк - т.е. 5 вложенных фигурных скобок без кода между ними считаются одной строкой.
Я также смиренно предположил бы, что любой показатель производительности, который на самом деле зависит от значения LoC, является двухъярусным:)
Любой день, когда я могу закончить с меньшим количеством строк кода, но с большим или большим количеством рабочих функций... это хороший день. Возможность удалить сотни строк кода и получить что-то такое же функциональное и более удобное в обслуживании, это замечательная вещь.
При этом, если у вас нет очень строгих правил кодирования в вашей команде, физические строки кода - бесполезная статистика. Логические строки кода по-прежнему бесполезны, но, как минимум, не вводят в заблуждение.
Если вы используете LOC в качестве меры производительности, вы внезапно обнаружите, что ваши программисты гораздо более многословно пишут "игра в систему". Это глупая мера, и только глупые люди используют ее для чего-то большего, чем просто хвастовство.
1 строка = 4 секунды чтения. Если требуется больше, чем это, чтобы понять, что я говорю по этой строке, строка слишком длинная.
"Строки кода" должны включать все, что вы должны поддерживать. Это включает в себя комментарии, но исключает пробелы.
Если вы используете это как показатель производительности, убедитесь, что вы делаете разумные сравнения. Строка C++ отличается от строки Ruby.
Вы должны думать о " потраченных строках кода", а не о "произведенных строках кода".
Все должно быть как можно проще, поэтому создание положительного теста на основе количества строк поощряет плохой код.
Кроме того, некоторые очень сложные вещи в конечном итоге решаются с помощью очень небольшого количества кода, а некоторые очень простые (например, стандартный код, например, методы получения и установки) могут добавить много строк за очень короткое время.
Что касается исходного вопроса, если бы я собирался считать строки, я бы включал каждую строку, кроме последовательных пустых строк. Я бы также добавил комментарии, так как они (надеюсь) полезная документация.
LOC - заведомо неоднозначная метрика. Для подробного сравнения он действителен только при сравнении кода, написанного на том же языке, с тем же стилем, той же командой.
Тем не менее, он обеспечивает определенное понятие сложности, когда рассматривается в представлении о порядке величины. Программа на 10000 строк намного сложнее, чем программа на 100 строк.
Преимущество LOC заключается в том, что wc -l возвращает его, и в отличие от многих других программных метрик, в его понимании или расчете нет никакой изощренности.
Там нет правильного ответа.
Для неофициальных оценок я использую wc -l.
Если бы мне нужно было что-то строго измерить, я бы измерил исполняемые операторы. Почти все, что с оператором-терминатором (обычно точкой с запятой) или оканчивается блоком. Для составных утверждений я бы посчитал каждое подзаголовок.
Так:
int i = 7; # one statement terminator; one (1) statement
if (r == 9) # count the if as one (1) statement
output("Yes"); # one statement terminator; one (1) statement; total (2) for the if
while (n <= 14) { # count the while as one (1) statement
output("n = ", n); # one statement terminator; one (1) statement
do_something(); # one statement terminator; one (1) statement
n++ # count this one, one statement (1), even though it doesn't need a statement terminator in some languages
} # brace doesn't count; total (4) for the while
Если бы я делал это в Scheme или Lisp, я бы посчитал выражения.
Как уже говорили другие, самое главное, чтобы ваш счет был последовательным. Также важно, для чего вы это используете. Если вы просто хотите, чтобы потенциальный новый сотрудник знал, насколько велик ваш проект, используйте wc -l. Если вы хотите заняться планированием и оценкой, возможно, вы захотите стать более формальными. Вы не должны ни при каких обстоятельствах использовать LOC для расчета компенсации программисту.
Понятие LOC - это попытка количественно определить объем кода. Как указывалось в других ответах, не имеет значения, что вы конкретно называете строкой кода, если вы последовательны. Интуитивно кажется, что программа из 10 строк меньше, чем программа из 100 строк, которая меньше, чем программа из 1000 строк и так далее. Вы можете ожидать, что для создания, удаления и поддержки 100-строчной программы требуется меньше времени, чем для 1000-строчной. Неформально, по крайней мере, вы можете использовать LOC, чтобы получить приблизительное представление о количестве работы, необходимой для создания, отладки и поддержки программы определенного размера.
Конечно, есть места, где это не держится. Например, сложный алгоритм, отображаемый в 1000 строк, может быть намного сложнее разработать, чем, скажем, простая программа базы данных, которая потребляет 2500 строк.
Таким образом, LOC - это грубая мера объема кода, которая позволяет менеджерам получить разумное понимание масштабов проблемы.
Я использую wc -l для быстрой оценки сложности рабочего пространства. Тем не менее, как показатель производительности LOC является худшим. Я вообще считаю, что это очень продуктивный день, если мой, если LOC счетчик идет вниз.
Я думаю об этом как о едином обрабатываемом утверждении. Например
(1 строка)
Dim obj as Object
(5 строк)
If _amount > 0 Then
_amount += 5
Else
_amount -= 5
End If
Я знаю, что некоторые люди используют LoC в качестве меры производительности
Не могли бы вы сказать мне, кто они, чтобы я не работал с ними (или, что еще хуже, с ними)?
Если я могу реализовать в 1400 строк, используя Haskell, то, что я мог бы реализовать в 2800 строк, используя C, я более продуктивен в C или Haskell? Что займет больше времени? Какие из них будут иметь больше ошибок (подсказка: это линейно по количеству LOC)?
Ценность программиста заключается в том, насколько изменяется его код (в том числе от или к пустой строке), увеличивая число в нижней строке. Я не знаю хорошего способа измерить или приблизить это. Но я знаю, что любая разумно измеримая метрика может быть использована, и она не отражает то, что вы действительно хотите. Так что не используйте это.
При этом, как вы считаете, LOCs? Простой, использовать wc -l, Почему это правильный инструмент? Что ж, вы, вероятно, не заботитесь о каком-то конкретном числе, но об общих общих тенденциях (повышение или понижение и насколько), об отдельных тенденциях (повышение или понижение, смена направления, как быстро, ...) и о почти все, кроме числа 82 763.
Различия между тем, что измеряют инструменты, вероятно, не интересны. Если у вас нет доказательств того, что число, выплевываемое вашим инструментом (и только этим инструментом), соотносится с чем-то интересным, используйте его в качестве приблизительного числа; все, кроме монотонности, следует брать не только с зерном, но и с солью.
Посчитай сколько раз '\n' происходит. Другие интересные персонажи могут быть ';', '{' а также '/',
Я согласен с принятым ответом Крейга Н, однако я хотел бы добавить, что в школе меня учили, что пробелы, комментарии и объявления не должны рассматриваться как "строки кода" с точки зрения измерения строк кода производится программистом в целях повышения производительности, то есть по старому правилу "15 строк в день".
Полезный код, который вы можете использовать в оболочке Windows Power:
(GCI -include *.c -recurse | select-string .).Count
В мире.NET, похоже, существует глобальное соглашение о том, что строка кода (LoC) является точкой последовательности отладки. Точка последовательности - это единица отладки, это часть кода, выделенная темно-красным цветом при установке точки останова. С точкой последовательности мы можем говорить о логическом LoC, и эту метрику можно сравнить по различным языкам.NET. Метрика логического кода LoC поддерживается большинством инструментов.NET, включая метрику кода VisualStudio, NDepend или NCover.
Метод 8 LoC (точки последовательности в начальных и конечных скобках не учитываются):

В отличие от физического LoC (имеется в виду просто подсчет количества строк в исходном файле), логический LoC имеет огромное преимущество - он не зависит от стиля кодирования. Мы все согласны с тем, что стиль кодирования может варьировать физический подсчет LoC на порядок от одного разработчика к другому. Я написал более подробный пост в блоге на эту тему: Как вы подсчитываете количество строк кода (LOC)?
Я согласен с постами, в которых говорится, что об этом сообщается во многих отношениях, и это не важный показатель. Посмотрите на эту информацию, когда разработчики получают оплату за строку кода.
Использование LOC для измерения производительности программиста похоже на оценку качества картины по ее размеру. Насколько я понимаю, единственная "ценность" LOC - это произвести впечатление на ваших клиентов и напугать ваших конкурентов.
Тем не менее, я думаю, что количество скомпилированных инструкций будет наименее неоднозначным. Тем не менее, плохие программисты имеют преимущество в том, что они, как правило, пишут излишне подробный код. Я помню, как однажды заменил 800+ строк действительно плохого кода на 28 строк. Это делает меня бездельником?
Любой менеджер проекта, который использует LOC в качестве основного показателя производительности, - это идиот, который заслуживает плохих программистов.
- LOCphy: физически линии
- LOCbl: Пустые строки Комментарблоки werden als Kommentarzeile gezählt
- LOCpro: строки программирования (объявления, определения, директивы и код)
- LOCcom: строки комментариев
Многие доступные инструменты дают информацию о проценте заполненных строк и так далее.
Нужно просто посмотреть на это, но не только рассчитывать на это.
LOC сильно растет на старте проекта и часто уменьшается после обзоров;)
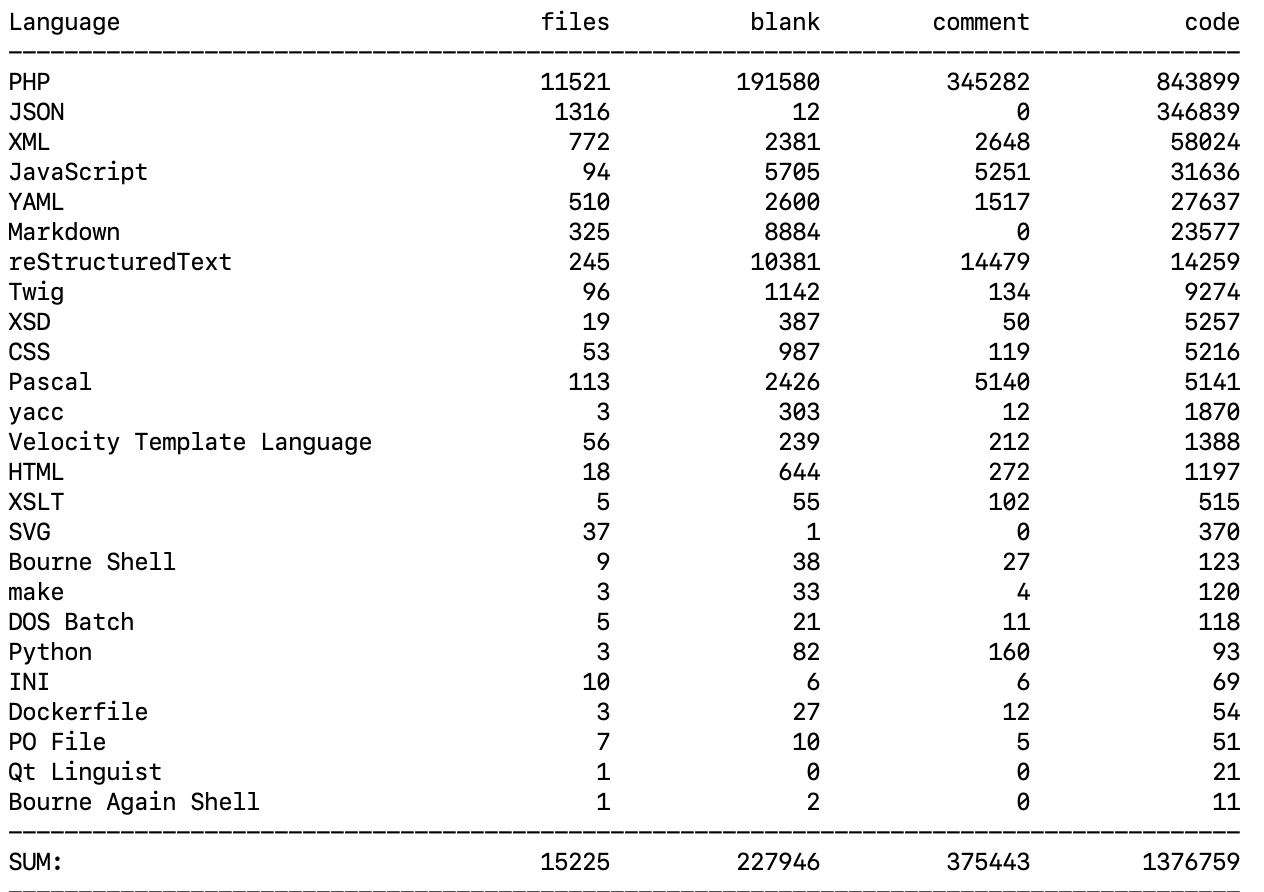
Я настоятельно рекомендую cloc tool для этой работы. Он считает строки для многих языков.
https://github.com/AlDanial/cloc#quick-start-
Я использовал для нашей компании и мне понравился этот инструмент. поделюсь сс из вывода;