Какой метод кроссовера я должен использовать для пересечения выражений Postfix в генетическом алгоритме?
Я строю проект, основной целью которого является поиск заданного числа (если возможно, в противном случае наиболее близкого) с использованием 6 заданных чисел и основных операторов (+, -, *, /). Идея состоит в том, чтобы случайным образом генерировать выражения, используя заданные числа и операторы, в обратной польской (постфиксной) нотации, потому что я нашел, что проще всего генерировать и вычислять позже. Эти выражения индивидуальны в популяции моего генетического алгоритма. Эти выражения имеют форму ArrayList строк в Java, где строки - это и операторы, и операнды (данные числа).
Основной вопрос здесь заключается в том, что будет лучшим методом для пересечения этих лиц (на самом деле выражения postfix)? Прямо сейчас я думаю о пересечении выражений, которые составлены из всех шести заданных операндов (и 5 операторов с ними). Позже я, вероятно, также перейду выражения, которые будут сделаны из меньшего количества операндов (5, 4, 3, 2, а также только 1), но я предполагаю, что сначала я должен выяснить это, как наиболее сложный случай (если вы думаю, что может быть лучше начать иначе, я открыт для любых предложений). Итак, дело в том, что каждое выражение состоит из всех заданных операндов, а также в дочернем выражении должны быть включены все операнды. Я понимаю, что для этого требуется какой-то упорядоченный кроссовер (часто используемый в таких задачах, как TSP), и я много читал об этом (например, здесь, где описано несколько методов), но я не совсем понял, какой из них лучше в моем случае (я также знаю, что в генетических алгоритмах много процессов "проб и ошибок", но я говорю здесь о другом).
То, что я говорю, беспокоит меня, это операторы. Если бы у меня был только список операндов, то не было бы проблемой скрестить 2 таких списка, например, взять случайный подмассив из половины элементов от одного родителя и заполнить остальные оставшимися элементами из родителя 2, сохраняя порядок следующим образом это было. Но здесь, если я, скажем, возьму первую половину выражения из первого родительского выражения, мне определенно придется заполнить дочернее выражение оставшимися операндами, но что мне делать с операторами? Возьмите их из родительского 2, как оставшиеся операнды (но тогда я должен был бы остерегаться, потому что для использования оператора в выражении постфикса мне нужно иметь как минимум на 1 операнд больше, и проверять, что все время может занимать много времени, или нет?) или, может быть, я мог бы генерировать случайные операторы для остальной части дочернего выражения (но тогда это был бы не просто кроссовер)?
Когда речь идет о кроссовере, есть и мутация, но, думаю, у меня все получилось. Я могу взять выражение и выполнить мутацию, при которой я просто переключу 2 операнда, или возьму выражение и случайным образом поменяю 1 или более операторов. Для этого у меня есть некоторые идеи, но кроссовер - это то, что действительно беспокоит меня.
Итак, это в значительной степени подводит итог моей проблемы. Как я уже сказал, главный вопрос - как пересечься, но если у вас есть какие-либо другие предложения или вопросы по поводу программы (возможно, более простое представление выражений - кроме списка строк), которое может быть легче / быстрее пересекаться, может быть, что-то я не сделал не упоминать здесь, это не имеет значения, может быть, даже совершенно новый подход к проблеме?), я бы хотел услышать их. Я не дал здесь никакого кода, потому что я не думаю, что это необходимо для ответа на этот вопрос, но если вы думаете, что это поможет, я определенно отредактирую, чтобы решить эту проблему. Еще раз, основной вопрос заключается в том, чтобы ответить, как пересечь эту конкретную часть проблемы (ожидается идея или псевдокод, хотя сам код тоже был бы великолепен:D), но если вы думаете, что мне нужно что-то изменить больше, или вы знаете некоторые другие решения всей моей проблемы, не стесняйтесь говорить.
Заранее спасибо!
1 ответ
На ум приходят два подхода:
Подход № 1
Закодируйте каждый геном как выражение фиксированной длины, где нечетные индексы являются числами, а четные индексы являются операторами. Для мутации вы можете немного изменить числа и / или поменять операторов.
Плюсы:
- Очень просто кодировать
Минусы:
- Пришлось бы создать инфиксный парсер
- Выражения фиксированной длины
Подход № 2
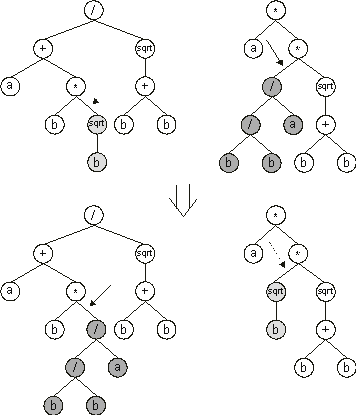
Закодируйте каждый геном как синтаксическое дерево. Например, 4 + 3 / 2 - 1 эквивалентно Add(4, Subtract(Divide(3, 2), 1)) который выглядит как:
_____+_____
| |
4 ____-____
| |
__/__ 1
| |
3 2
Затем при переходе выберите случайный узел из каждого дерева и поменяйте их местами. Для мутации вы можете добавлять, удалять и / или изменять случайные узлы.
Плюсы:
- Может найти лучшие результаты
- Выражения переменной длины
Минусы:
- Добавляет сложность времени
- Добавляет сложность программирования
Вот пример второго подхода: