Рабочий процесс для создания изменяющихся во времени ковариат в r
У меня есть огромный файл данных в длинном формате, его части представлены ниже. Каждый идентификатор может иметь несколько строк, где статус - это окончательный статус. Однако мне нужно провести анализ с изменяющимися во времени ковариатами и, следовательно, нужно создать две новые переменные времени и обновить переменную состояния. Я боролся с этим в течение некоторого времени и не могу понять, как это сделать эффективно, поскольку на один идентификатор может приходиться до четырех строк. Изменяющаяся во времени переменная NUM.AFTER.DIAG, Если NUM.AFTER.DIAG==0 тогда легко, где time1=0 а также time2=STATUSDATE, Однако когда NUM.AFTER.DIAG==1 тогда мне нужно сделать новый ряд, где time1=0, time2=DOB-DATE.DIAG а также NUM.AFTER.DIAG=0 а также убедитесь, что STATUS="B", Второй ряд будет тогда time1=time2 из предыдущего ряда и time2=STATUSDATE-DATE.DIAG-time1 из этого ряда. В равной степени, если строк больше, разные строки должны быть вычтены друг из друга. Также, если NUM.AFTER.DIAG==0, но есть несколько строк, все дополнительные строки могут быть удалены.
Есть идеи для эффективного решения этой проблемы? Я посмотрел на команду разворачивания Джона Фокса, но она предполагает, что все интервалы в широком формате для начала.
Изменить: таблица в соответствии с просьбой. Что касается цензорной переменной: "D"= событие (смерть)
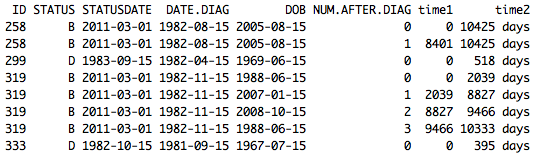
structure(list(ID = c(187L, 258L, 265L, 278L, 281L, 281L, 283L,
283L, 284L, 291L, 292L, 292L, 297L, 299L, 305L, 305L, 311L, 311L,
319L, 319L, 319L, 322L, 322L, 329L, 329L, 333L, 333L, 333L, 334L,
334L), STATUS = c("D", "B", "B", "B", "B", "B", "D", "D", "B",
"B", "B", "B", "D", "D", "D", "D", "B", "B", "B", "B", "B", "D",
"D", "B", "B", "D", "D", "D", "D", "D"), STATUSDATE = structure(c(11153,
15034, 15034, 15034, 15034, 15034, 5005, 5005, 15034, 15034,
15034, 15034, 6374, 5005, 7562, 7562, 15034, 15034, 15034, 15034,
15034, 7743, 7743, 15034, 15034, 4670, 4670, 4670, 5218, 5218
), class = "Date"), DATE.DIAG = structure(c(4578, 4609, 4578,
4487, 4670, 4670, 4517, 4517, 4640, 4213, 4397, 4397, 4397, 4487,
4213, 4213, 4731, 4731, 4701, 4701, 4701, 4397, 4397, 4578, 4578,
4275, 4275, 4275, 4456, 4456), class = "Date"), DOB = structure(c(NA,
13010, NA, NA, -1082, -626, 73, 1353, 13679, NA, 1626, 3087,
-626, -200, 2814, 3757, 1930, 3787, 6740, 13528, 14167, 5462,
6557, 7865, 9235, -901, -504, -108, -535, -78), class = "Date"),
NUM.AFTER.DIAG = c(0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 2, 3, 1, 2, 1, 2, 0, 0, 0, 0, 0)), .Names = c("ID",
"STATUS", "STATUSDATE", "DATE.DIAG", "DOB", "NUM.AFTER.DIAG"), row.names = c(NA,
30L), class = "data.frame")
РЕДАКТИРОВАТЬ: Я пришел к решению, хотя, вероятно, не очень эффективно.
u1<-ddply(p,.(ID),function(x) {
if (x$NUM.AFTER.DIAG==0){
x$time1<-0
x$time2<-x$STATUSDATE-x$DATE.DIAG
x<-x[1,]
}
else {
x<-rbind(x,x[1,])
x<-x[order(x$DOB),]
u<-max(x$NUM.AFTER.DIAG)
x$NUM.AFTER.DIAG<-0:u
x$time1[1]<-0
x$time2[1:(u)]<-x$DOB[2:(u+1)]-x$DATE.DIAG[2:(u+1)]
x$time2[u+1]<-x$STATUSDATE[u]-x$DATE.DIAG[u]
x$time1[2:(u+1)]<-x$time2[1:u]
x$STATUS[1:u]<-"B"
}
x
}
)
1 ответ
Хорошо, я что-то пробовал, но я не уверен, что полностью понимаю ваш процесс трансформации, поэтому дайте мне знать, если есть какие-то ошибки. В общем ddply будет медленным (даже когда .parallel = TRUE), когда есть много людей, главным образом потому, что в конце необходимо объединить все наборы данных всех людей и rbind (или же rbind.fill) их, что занимает целую вечность для множества data.frame объекты.
Так вот предложение, где dat.orig ваш набор данных игрушек:
Я бы сначала разделил задачу на две части: 1) NUM.AFTER.DIAG == 02) NUM.AFTER.DIAG == 1
1) кажется, что если NUM.AFTER.DIAG == 0кроме вычисления времени2 и извлечения первой строки, если идентификатор встречается более одного раза (например, идентификатор 333), в части 1 делать особо нечего:
## erase multiple occurences
dat <- dat.orig[!(duplicated(dat.orig$ID) & dat.orig$NUM.AFTER.DIAG == 0), ]
dat0 <- dat[dat$NUM.AFTER.DIAG == 0, ]
dat0$time1 <- 0
dat0$time2 <- difftime(dat0$STATUSDATE, dat0$DATE.DIAG, unit = "days")
time.na <- is.na(dat0$DOB)
dat0$time1[time.na] <- dat0$time2[time.na] <- NA
> dat0
ID STATUS STATUSDATE DATE.DIAG DOB NUM.AFTER.DIAG time1 time2
1 187 D 2000-07-15 1982-07-15 <NA> 0 NA NA days
3 265 B 2011-03-01 1982-07-15 <NA> 0 NA NA days
4 278 B 2011-03-01 1982-04-15 <NA> 0 NA NA days
5 281 B 2011-03-01 1982-10-15 1967-01-15 0 0 10364 days
7 283 D 1983-09-15 1982-05-15 1970-03-15 0 0 488 days
10 291 B 2011-03-01 1981-07-15 <NA> 0 NA NA days
11 292 B 2011-03-01 1982-01-15 1974-06-15 0 0 10637 days
13 297 D 1987-06-15 1982-01-15 1968-04-15 0 0 1977 days
14 299 D 1983-09-15 1982-04-15 1969-06-15 0 0 518 days
15 305 D 1990-09-15 1981-07-15 1977-09-15 0 0 3349 days
17 311 B 2011-03-01 1982-12-15 1975-04-15 0 0 10303 days
26 333 D 1982-10-15 1981-09-15 1967-07-15 0 0 395 days
29 334 D 1984-04-15 1982-03-15 1968-07-15 0 0 762 days
2) немного сложнее, но все, что вам на самом деле нужно сделать, это вставить еще одну строку и вычислить переменные времени:
## create subset with relevant observations
dat.unfold <- dat[dat$NUM.AFTER.DIAG != 0, ]
## compute time differences
time1 <- difftime(dat.unfold$DOB, dat.unfold$DATE.DIAG, unit = "days")
time1[time1 < 0] <- 0
time2 <- difftime(dat.unfold$STATUSDATE, dat.unfold$DATE.DIAG, unit = "days")
## calculate indices for individuals
n.obs <- daply(dat.unfold, .(ID), function(z) max(z$NUM.AFTER.DIAG) + 1)
df.new <- data.frame(ID = rep(unique(dat.unfold$ID), times = n.obs))
rle.new <- rle(df.new$ID)
ind.last <- cumsum(rle.new$lengths)
ind.first <- !duplicated(df.new$ID)
ind.first.w <- which(ind.first)
ind.second <- ind.first.w + 1
ind2.to.last <- unlist(sapply(seq_along(ind.second),
function(z) ind.second[z]:ind.last[z]))
## insert time variables
df.new$time2 <- df.new$time1 <- NA
df.new$time1[ind.first] <- 0
df.new$time1[!ind.first] <- time1
df.new$time2[!ind.first] <- time2
df.new$time2[ind2.to.last - 1] <- time1
это дает мне:
> df.new
ID time1 time2
1 258 0 8401
2 258 8401 10425
3 284 0 9039
4 284 9039 10394
5 319 0 2039
6 319 2039 8827
7 319 8827 9466
8 319 9466 10333
9 322 0 1065
10 322 1065 2160
11 322 2160 3346
12 329 0 3287
13 329 3287 4657
14 329 4657 10456
Это должно работать для STATUS переменная и другие переменные аналогичным образом. Когда оба шага работают по отдельности, вам просто нужно сделать один rbind шаг в конце.